Lộ diện công cụ AI chuyển văn bản thành video trong vài giây, chỉ cần nhập lời nhắc sẽ nhận lại nội dung theo đúng yêu cầu
24/03/2023 15:38 GMT+7 | HighTech

Theo trang Bloomberg, đây là lần đầu tiên người dùng đại chúng được chứng kiến khả năng của một công cụ chuyển đổi văn bản thành video nhờ AI.
Trí tuệ nhân tạo đã và đang đạt được tiến bộ đáng kể với hình ảnh dạng tĩnh, vốn được tạo ra từ 'đề bài' là văn bản. Trong vài tháng kể từ khi ra mắt, các dịch vụ tạo ảnh từ văn bản như Dall-E và Stable Diffusion đã tạo ra những bức ảnh đẹp, hấp dẫn, với độ chân thực đáng kinh ngạc, khiến không ít người dùng khó có thể phân biệt thực - ảo.
Giờ đây, Runway - một công ty khởi nghiệp có trụ sở tại New York tiếp tục 'thị uy' sức mạnh của trí tuệ nhân tạo lên một tầm cao mới: Tạo ra video từ văn bản.
Theo đó, vào đầu tuần này, Runway đã hé lộ Gen 2 – một hệ thống AI có thể tạo ra các đoạn video từ một vài lời nhắc (prompt) của người dùng. Giống như các công cụ AI khác (như ChatGPT), người dùng chỉ cần nhập mô tả về những gì họ muốn tạo ra (Ví dụ: Một con người đi trong mưa), Gen 2 sẽ tạo ra một video dài khoảng 3 giây, với khung cảnh trong video giống hoặc gần tương tự như như nội dung yêu cầu. Ngoài lời nhắc dạng văn bản, người dùng có thể tải lên một hình ảnh để làm tham chiếu cho hệ thống tạo video bằng AI này.

Đoạn video ngắn được tạo ra dựa trên lời nhắc có nội dung: "Hoàng hôn qua cửa sổ trong một căn hộ ở New York". Ảnh: Runway
Theo Bloomberg, việc Runway trình làng Gen 2 cũng đánh dấu lần đầu tiên người dùng đại chúng được chứng kiến khả năng của một công cụ chuyển đổi văn bản thành video nhờ AI. Trước Runway, các ông lớn như Google và Meta vào năm ngoái cũng đã hé lộ công nghệ chuyển văn bản thành video. Tuy nhiên, những dự án này hoặc mới chỉ dừng lại ở giai đoạn nghiên cứu, hoặc chưa có kế hoạch công bố công khai.
Về phần Runway, startup này đã nghiên cứu các công cụ AI từ năm 2018 và đã huy động được 50 triệu USD vào cuối năm ngoái. Khá thú vị, Runway thực chất đã giúp tạo ra phiên bản gốc của Stable Diffusion, trước khi công cụ chuyển văn bản thành hình ảnh nổi tiếng này được công ty Stability AI phổ biến và phát triển thêm.
Trong một bản demo trực tiếp độc quyền vào tuần trước với đồng sáng lập và CEO của Runway là Cris Valenzuela, phóng viên của Bloomberg đã thử nghiệm Gen 2 bằng cách đưa ra lời nhắc có nội dung: "Cảnh quay bằng máy bay không người lái về khung cảnh sa mạc".

Video được tạo ra bằng lời nhắc"Cảnh quay bằng máy bay không người lái về khung cảnh sa mạc". Ảnh: Runway
Trong vòng vài phút, Gen 2 đã tạo một video chỉ dài vài giây, với chất lượng hình ảnh không được rõ nét. Tuy nhiên, nội dung trong video thực sự đúng như lời nhắc, với cảnh quay bằng máy bay không người lái được quay trên khung cảnh sa mạc.
Phóng viên của Bloomberg có thể thấy rõ được bầu trời xanh và những đám mây trôi lập lờ ở phía chân trời, và cảnh mặt trời mọc (hoặc có lẽ là lặn), ở góc bên phải của khung hình video, những tia sáng của nó làm nổi bật những đụn cát màu nâu bên dưới.
Một số video khác mà Runway tạo ra từ lời nhắc của chính nó cho thấy một số điểm mạnh và điểm yếu hiện tại của hệ thống này. Chẳng hạn, một video quay cận cảnh nhãn cầu trông sắc nét và khá giống con người; trong khi một đoạn clip khác về cảnh một người đang đi bộ xuyên qua một khu rừng cho thấy Gen 2 vẫn gặp khó khăn trong việc tạo ra chuyển động cơ thể và tạo hình tay chân con người chân thực nhất có thể.

Một video ví dụ khác được tạo bởi mô hình Gen-2 của Runway. Lời nhắc nhập văn bản là “Một cảnh quay theo sau một người đang vượt qua bụi rậm trong rừng.” Ảnh: Runway
Theo thừa nhận của CEO Valenzuela, Gen 2 vẫn chưa hoàn toàn "tìm ra" cách mô tả chính xác các vật thể đang chuyển động.
"Bạn có thể tạo ra một cuộc rượt đuổi bằng ô tô, nhưng đôi khi những chiếc ô tô có thể bay đi", người sáng lập của Runway cho biết.
Đáng chú ý, nếu như các mô hình chuyển văn bản thành hình ảnh như DALL-E hoặc Stable Diffusion thường ưa chuộng các lời nhắc 'dài dòng', vốn có thể dẫn tới hình ảnh đầu ra chi tiết hơn, Gen 2 lại đi theo hướng ngược lại.
Theo đó, người dùng cần tạo ra các lời nhắc càng đơn giản càng tốt với Gen 2. Theo Runway, Gen 2 là một cách cung cấp cho các nghệ sĩ, nhà thiết kế và nhà làm phim một công cụ khác có thể giúp họ thực hiện các quy trình sáng tạo của mình và làm cho những công cụ đó có giá cả phải chăng và dễ tiếp cận hơn so với trước đây.
Được biết thêm, Gen 2 được xây dựng dựa trên mô hình AI hiện có có tên là Gen 1, vốn từng được Runway thử nghiệm giới hạn trên Discord vào tháng Hai vừa qua, với sự tham gia của hàng nghìn người dùng.
Mô hình AI Gen 1 yêu cầu người dùng tải video lên làm nguồn đầu vào mà nó sẽ sử dụng (cùng với hướng dẫn từ phía người dùng như lời nhắc văn bản hoặc ảnh tĩnh) để tạo ra một video 3 giây, không có tiếng. Ví dụ: Bạn có thể tải lên hình ảnh một chú mèo đang đuổi theo một món đồ chơi cùng với dòng chữ "lông xoăn một cách dễ thương" và Gen 1 sẽ tạo một video về một chú mèo có kiểu lông 'xoăn tít' đang đuổi theo một món đồ chơi.
Các video được tạo bằng mô hình AI Gen 2 hiện không có tiếng, nhưng Runway cho biết công ty đang nghiên cứu về công nghệ tạo âm thanh với hy vọng cuối cùng sẽ tạo ra một hệ thống có thể tạo được cả hình lẫn âm.
Ở thời điểm hiện tại, Gen 2 vẫn chưa được cung cấp rộng rãi cho tất cả người dùng. Thay vào đó, người dùng sẽ phải đăng ký vào danh sách chờ để được tham gia đợt thử nghiệm có giới hạn.
Tham khảo Bloomberg
-
 18/11/2024 21:46 0
18/11/2024 21:46 0 -

-
 18/11/2024 21:13 0
18/11/2024 21:13 0 -

-
 18/11/2024 20:26 0
18/11/2024 20:26 0 -
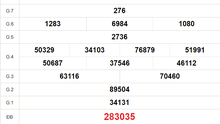
 18/11/2024 20:22 0
18/11/2024 20:22 0 -

-
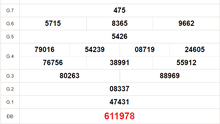
-

-
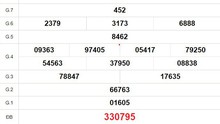
-
 18/11/2024 20:09 0
18/11/2024 20:09 0 -
-
-

-

-
 18/11/2024 19:11 0
18/11/2024 19:11 0 -

-

-

-
 18/11/2024 18:00 0
18/11/2024 18:00 0 - Xem thêm ›